Learning Goals from Failure
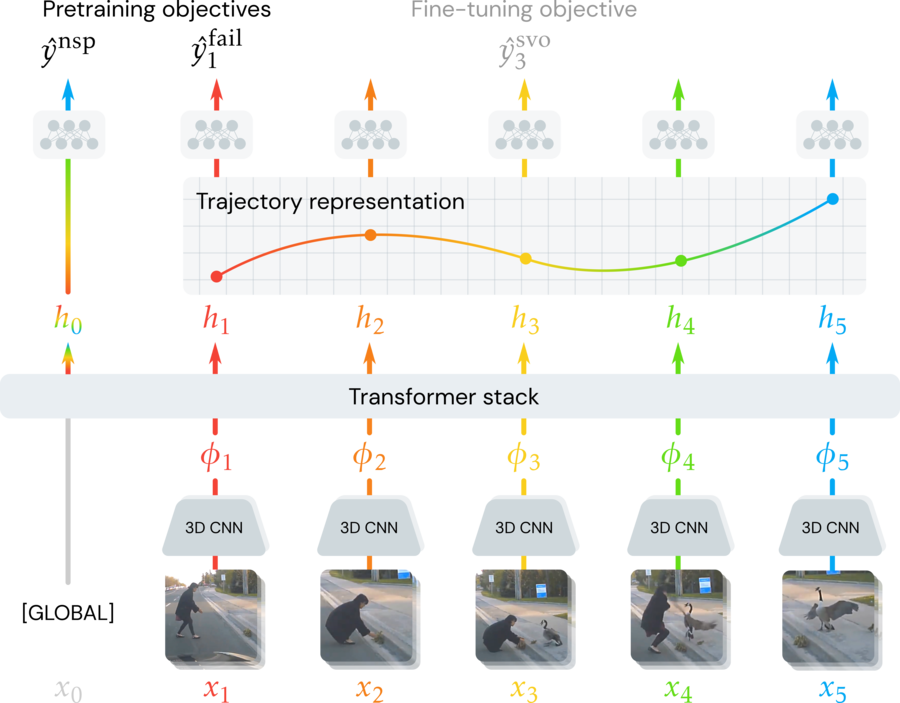
We introduce a framework that predicts the goals behind observable human action in video. Motivated by evidence in developmental psychology, we leverage video of unintentional action to learn video representations of goals without direct supervision. Our approach models videos as contextual trajectories that represent both low-level motion and high-level action features.
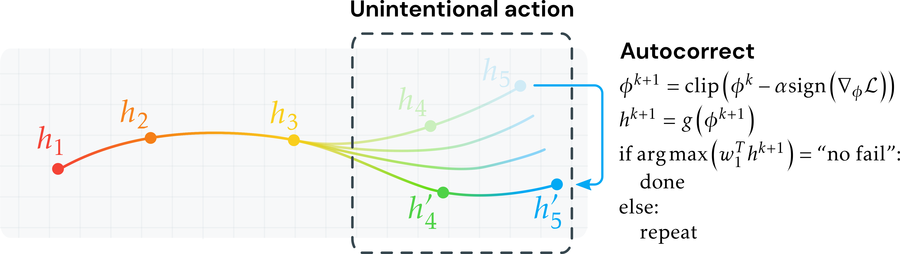
Experiments and visualizations show our trained model is able to predict the underlying goals in video of unintentional action. We also propose a method to ``automatically correct'' unintentional action by leveraging gradient signals of our model to adjust latent trajectories. Although the model is trained with minimal supervision, it is competitive with or outperforms baselines trained on large (supervised) datasets of successfully executed goals, showing that observing unintentional action is crucial to learning about goals in video.
Paper

Results
Goal predictions
Failure recognition
Decoding learned trajectories: We freeze our trained model and train a linear decoder to describe the goals of action, outputting subject-verb-object (SVO) triples. The decoder predicts the goals of video when the action shown is intentional (lefttop) and predicts unintentional failures when they appear (rightbottom).
Action autocorrect
Retrieval from auto-corrected trajectories: We show the nearest neighbors from auto-corrected action trajectories, using our proposed adversarial method. The retrievals are computed across both the Oops! and Kinetics datasets. The corrected representations yield corrected trajectories that are often embedded close to action depicting the same high-level goal's successful completion.
Analyzing the representation
Unsupervised action neurons emerge: We show the neurons with highest correlation to the words in the subject-verb-object vocabulary, along with their top-5 retrieved clips. Neurons that detect intentions across a wide range of action and scene appear to emerge, despite only training with binary labels on the intentionality of action.
Data
We collect unconstrained natural language descriptions of a subset of videos in the Oops! dataset, prompting Amazon Mechanical Turk workers to answer “What was the goal in this video?” as well as “What went wrong?”. We then process these sentences to detect lemmatized subject verb object triples, manually correcting for common constructions such as “tries to X” (where the verb lemma is detected as “try”, but we would like “X”). The final vocabulary contains 3615 tokens. The obtained SVO triples can be used to evaluate video representations of goals. We show some examples to the leftabove.
Explore datasetArchitecture and code
Acknowledgements
Funding was provided by DARPA MCS, NSF NRI 1925157, and an Amazon Research Gift. We thank NVidia for donating GPUs.